


The riskiest startups to found, from an AI analysis of YC's entire portfolio
I built an app to compare any startup idea to its most similar YC companies

I’ve been using Nomic a lot to analyze unstructured data, such as looking for coverage gaps among the companies advertising on OpenAds’ network. Out of curiosity, I scraped and visualized ~5,000 YC companies, their descriptions, and their outcomes. TL;DR: here’s the app to analyze any startup by its description.

Visual thinking in 512 dimensions
This works by generating embeddings1 of each company’s description; reducing the dimensionality; visualizing the resulting clusters and inferring labels for them. The closer two dots appear, the more related the companies’ descriptions.
There are obvious clusters: the blue retail cluster is all the 10-minute grocery delivery startups founded after DoorDash. Aviation’s purple cluster is illustrative. The dense center of the southern subcluster is all electric passenger aircraft, and moving outward leads to more varied companies, like supersonic UAVs. The northeast aviation subcluster is space tech.
What’s hype now

If we filter by YC batch we can see the post-ChatGPT cohorts (S23+). We see which areas got hollowed out (retail, fintech, education) and which new areas are hot (Cellular engineering, anything to do with LLMs, AI for sales and customer support). At a glance, there’s actually a very wide variety of AI startups given the sparsity of their cluster, with some local clumps for similar LLM eval startups.
Risky business
But we’re here to learn which companies are predisposed to success or failure. Let’s change the coloring to reflect company status:
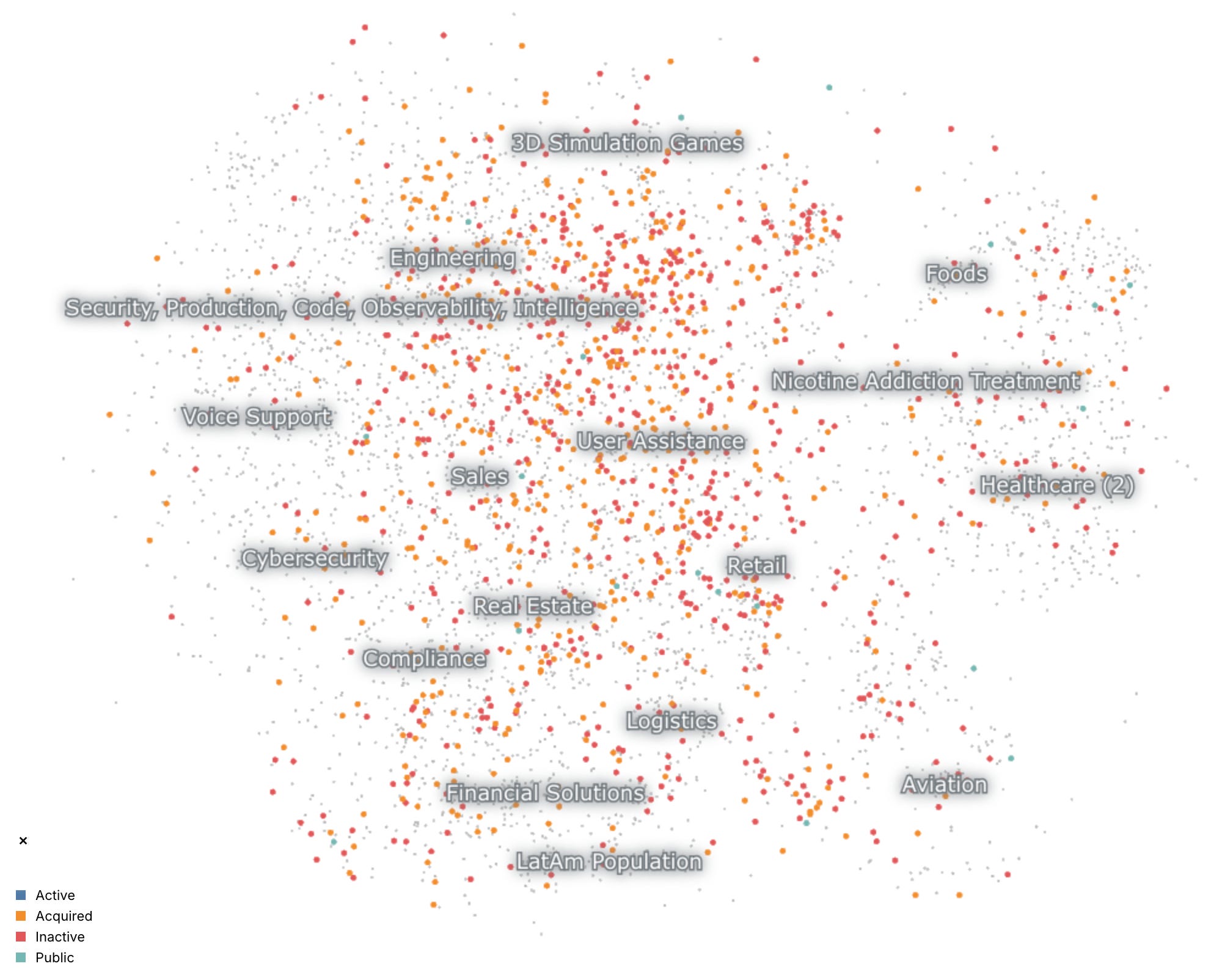
Orange = acquired, teal = IPO, red = dead. We’re graying out still-active startups to more clearly see the ones at the end of their journey.
Here’s a horrifying cluster:

This bloodbath was direct-to-consumer / social / retail / fashion. Everyone knows social is hard, and DTC is hard, so it follows that the combination is geometrically harder. These are still good bets for YC since a DTC/social home run will have a massive TAM, but if you’re a founder thinking of starting the next social fashion subscription box, you should be aware of all the skeletons in this region.

Risk-free business
Let’s find a happier region of vector space. Nothing but acquisitions here!

Turns out, starting an enterprise database software company is the surest path to acquisition. All you have to do is add “DB” to your name, and you can’t lose! (This could also be a function of such companies requiring such skilled tech talent that there’s always the off-ramp possibility of an acquihire.)

Modeling any startup’s prospects
“But what does this mean for my startup?” founders ask. “What about my portcos?” ask VCs. Well, I was stuck on a tarmac for 3 hours this Labor Day, so I built an analysis layer on top of the dataset. I call it, "YComparator”. Input a 1-5 sentence description of a startup, and it’ll find the 50 most similar startups in YC’s portfolio, look at their outcomes, and tell you how your idea ranks based on the outcomes of your nearest neighbors. The repo’s public if you want to dig into the methodology.

Take the percentile with a huge grain of salt,23 but the similar neighbors retrieved are useful for competitive research, identifying other founders to collaborate with, and getting a sense for the industry’s history – the sort of broad, “vibe” based background knowledge that used to only be obtainable by working in-industry. I expect investors will incorporate a similar process into their diligence, if only to get quick background vibes on comparable companies in a space.
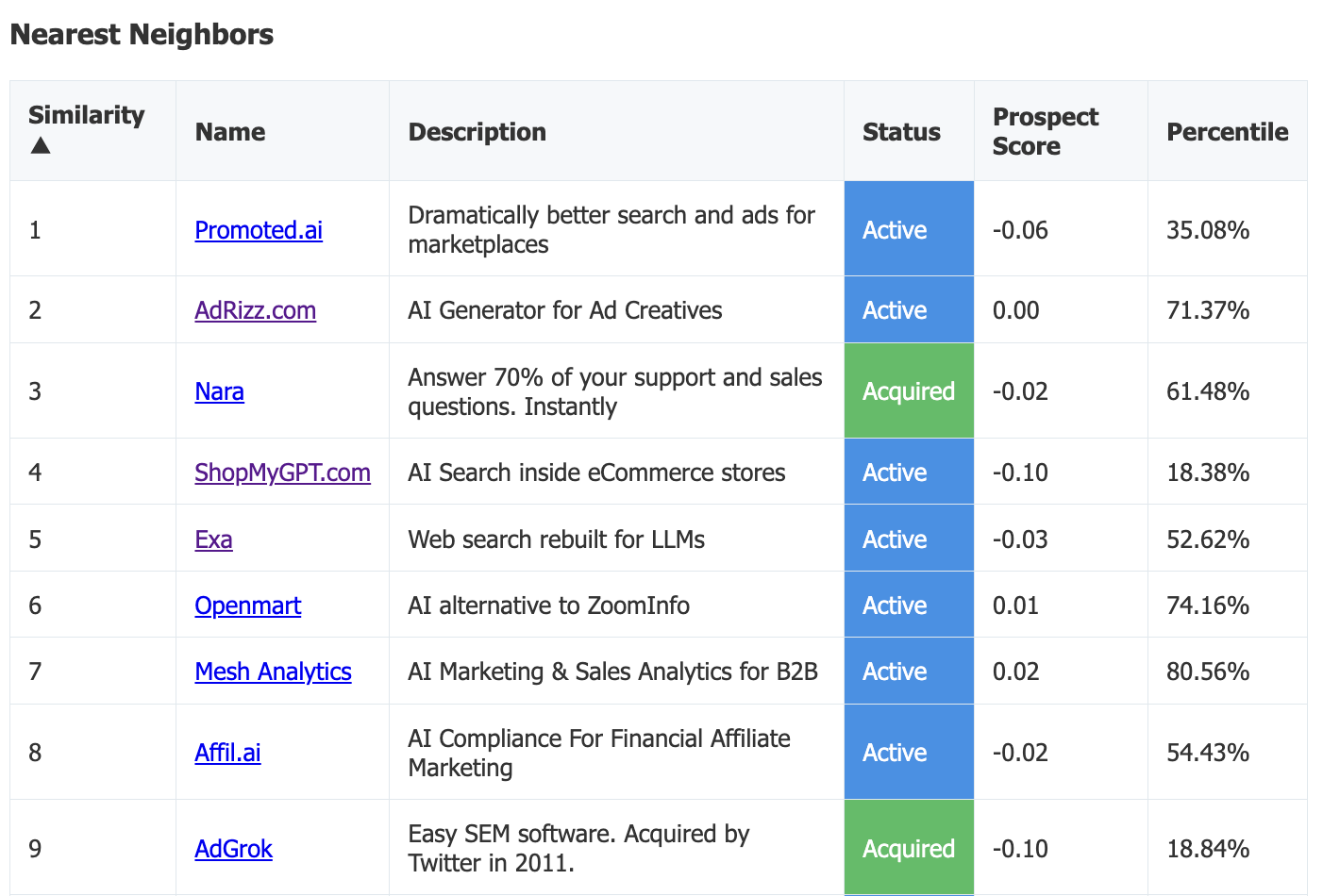
Test your might!

The distribution of raw success-propensities looks like this. There’s a long tail of “bad” ideas, but most calculations cluster around neutral, given that YC has expanded in recent years, so there’s more weight to new sectors without strong positive/negative signals. What’s interesting is the drop-off in the top quintile: there’s a very thin distribution of companies in the really good clusters.
🤑 The safest idea ever funded by YC? 🤑
“Scalable, cloud-ready relational database”
💀 The riskiest? 💀
“Mix and listen to user-shared music online”
Check out https://ycomparator.stevenliss.com/ and tag me (@this_liss) on Twitter. See how your company stacks up, or try to find the best/worst startup idea ever!
512 dimensional numerical representations of semantic meaning, or “vibes”
Ideally we’d weigh neighbors’ outcomes by similarity, but the curse of dimensionality makes this tricky. A good approach could be to dynamically analyze the kernel density for each subregion of KNNs to find a meaningful way to normalize the weights given different local sparsities, but my plane was taking off. You could also try using the precomputed prospects of the neighbors to pick up on less-local gradients, but there’s a risk of an echo chamber effect.
There’s a positive bias toward new companies since there’s been less time for them to fail.